Inhaltsverzeichnis:
Was auch immer man sagen mag, künstliche Intelligenz ist schon seit geraumer Zeit ein heißes Thema. Hin und wieder sehen wir in den Mainstream-Medien Nachrichten über die nächste bahnbrechende Version von ChatGPT, Berufe, die durch KI ersetzt werden sollen, oder die revolutionären Funktionen der künstlichen Intelligenz (sorry Apple Intelligence) in den neuesten Iphones. Es überrascht nicht, dass Artikel über KI Clickbait sind, da die Technologie mehr als einmal extreme Emotionen hervorruft. Manche sehen in ihr die Lösung für alle Probleme der Menschheit, von der globalen Erwärmung bis zur Ausrottung von Krankheiten. Andererseits weckt KI bei vielen Menschen Ängste, vor allem aufgrund eines falschen Verständnisses der Funktionsweise der Technologie.


Dieses Schema ist nicht neu; wir haben ähnliche Phänomene in der Vergangenheit bei der industriellen Revolution oder der Entwicklung der Elektrizität gesehen. So wie zu Beginn des 20. Jahrhunderts Fußgänger auf dem Bürgersteig Plakate sehen konnten, die sich gegen die Elektrifizierung aussprachen, können wir heute im Internet die Meinungen der Gegner der künstlichen Intelligenz lesen. Meiner Meinung nach sollten sowohl die Stimmen der KI-Befürworter als auch die der Gegner “durch zwei geteilt” werden, denn, wie das Sprichwort sagt, “Extreme sind schlecht”. Künstliche Intelligenz ist eine Chance für die Menschheit, sie kann bei der erwähnten Krankheitsforschung helfen und den Prozess der Entwicklung neuer Medikamente erheblich beschleunigen. Es ist jedoch auch wichtig, die Risiken im Auge zu behalten. KI unterstützt bereits Algorithmen, deren Aufgabe es ist, die nächsten Inhalte, die in populären sozialen Medien angezeigt werden, so genau wie möglich zu bestimmen. Über die Auswirkungen des so genannten Feeds auf den Menschen könnte man lange und ausgiebig diskutieren, aber welche Studien wir auch immer berücksichtigen, ihre Schlussfolgerung wird ähnlich sein: Soziale Medien machen süchtig und ihre langfristigen Auswirkungen auf unseren Verstand sind bestenfalls fraglich. Wir müssen uns fragen, ob es wirklich so ist, dass die Rechenleistung der künstlichen Intelligenz als ein weiteres System fungieren soll, das uns zu Vertretern des “homo ludens” macht, d.h. zu Menschen, deren Ziel nur darin besteht, “Inhalte” zu konsumieren und Spaß zu haben.
Doch egal, was wir sagen, nur eines ist sicher: Künstliche Intelligenz wird uns erhalten bleiben und ihre Bedeutung wird mit der Zeit nur noch zunehmen. Und unsere Aufgabe ist es nur, sie mit Vorsicht zu nutzen und uns ihrer dunklen Seiten bewusst zu sein.
Mathematische Annahmen

Die Idee der künstlichen Intelligenz ist nicht neu, schließlich haben sich die Menschen seit Jahrhunderten gefragt, ob es Wesen und später Geräte geben könnte, die im menschlichen Sinne des Wortes “intelligent” sind. Intelligenz selbst ist ein Konzept, das wir auf verschiedene Weise definieren können. Am häufigsten definieren wir Intelligenz als die Fähigkeit, Informationen zu verarbeiten, sie zu analysieren und logische Schlussfolgerungen zu ziehen. Es ist ein rein menschliches Konzept, das Eigenschaften wie Lernen, kognitive Fähigkeiten, Erkennen von Emotionen oder Kreativität umfasst. Darüber hinaus können wir auch zwischen tierischer Intelligenz, die u.a. aus Anpassungsfähigkeit besteht, und kollektiver Intelligenz unterscheiden, bei der Individuen eine einfache Verhaltensstruktur haben, aber als Gruppe komplexe Ziele erreichen. Darüber hinaus können wir Intelligenz in Bezug auf Technologie definieren. In diesem Fall sprechen wir von künstlicher Intelligenz, die Aspekte der menschlichen Intelligenz so gut wie möglich simuliert und zu reproduzieren versucht.
Obwohl das Thema der künstlichen Intelligenz in vielen kulturellen Texten angesprochen wurde, hat sich die wissenschaftliche Welt erst in den späten 1940er und frühen 1950er Jahren ernsthaft damit befasst. Zu dieser Zeit erschien die erste Generation von Wissenschaftlern, die von diesem Thema fasziniert waren, in der akademischen Szene. Einer von ihnen war der britische Gelehrte Alan Turing, der vorschlug, dass die Schaffung dessen, was wir als künstliche Intelligenz bezeichnen könnten, nicht sehr kompliziert sein sollte, denn “die Aufgabe der Vernunft besteht nur darin, Probleme zu lösen und Entscheidungen zu treffen, und auf ähnliche Weise können auch Maschinen handeln”. Es fällt schwer, nicht zuzustimmen, dass Turings Überlegungen in ihrer Einfachheit brillant waren. Kurz nach der Formulierung seiner Thesen veröffentlichte er 1950 ein Papier mit dem Titel ‘Computing Machinery and Intelligence’, in dem er sozusagen die mathematischen Voraussetzungen für das Funktionieren eines künstlichen Geistes darlegte. Doch während auf dem Papier alles vielversprechend aussah, gab es ein ziemlich großes Problem – die Technologie.

Zu Beginn der 1950er Jahre waren Computer teuer, kompliziert, ausfallsicher, energieintensiv und vor allem riesig, so dass sie sogar den Platz einer ziemlich großen Wohnung einnehmen konnten. Außerdem verfügten sie noch nicht über eine ausreichende Rechenleistung, aber das größte Problem war der Speicher. Vor 1949 verfügten Computer nicht darüber. Sie konnten nur Befehle ausführen, die auf einem externen Medium gespeichert waren, aber sie konnten sich nicht daran erinnern. Mit anderen Worten: Man konnte den Computern sagen, was sie tun sollten, aber sie konnten sich nicht daran erinnern, was sie taten.
Erfolge und Misserfolge
Obwohl Alan Turing ein Konzept vorstellte, das zu dieser Zeit unmöglich zu verwirklichen war, bedeutete dies nicht, dass es in der Zukunft auch so sein würde. Es war eine Zeit der galoppierenden Technologie, in der ständig neue Innovationen auftauchten und der Beginn eines technologischen Wettlaufs zwischen den USA und der UdSSR. Während die Technologie sozusagen in Richtung Zukunft eilte, wurde im Hintergrund das erste Symposium über die Idee der künstlichen Intelligenz organisiert, das von Allen Newell, Cliff Shaw und dem Logiktheoretiker Herbert Simon initiiert wurde. Es handelte sich um ein Programm, das von der Research and Development Corporation (RAND) finanziert wurde, um einen Ort für die Diskussion über KI zu schaffen. Trotz der Publicity erfüllte die Konferenz jedoch nicht die Erwartungen der meisten Wissenschaftler. Trotz zahlreicher Podiumsdiskussionen gab es keine Einigung über die Methoden zur Fortsetzung der KI-Forschung, aber in einem waren sich alle einig – KI ist erreichbar, vielleicht nicht heute, nicht morgen, aber die wachsende Bedeutung der Computerindustrie wird die KI zweifellos zum Blühen bringen.

Und so ging es weiter, von 1957 bis 1974 blühte die künstliche Intelligenz auf. Die Computer wurden immer komplexer, und damit wuchs auch ihre Rechenleistung. Die Kapazität der ersten Speicher wurde immer größer, und das Aufkommen von Halbleitern versprach fast grenzenlose Möglichkeiten. In einem ähnlichen Tempo wurden Konzepte der künstlichen Intelligenz entwickelt. Es entstanden die ersten Algorithmen für maschinelles Lernen, künstliche Neuronen, die zunächst auf Vakuumröhren basierten, und behelfsmäßige Sprachmodelle wie ‘Eliza’ von Joseph Weizenbaum. Interessant ist auch der sogenannte ‘Eliza-Effekt’, der mit diesem Projekt in Verbindung gebracht wird. Menschen, die zum ersten Mal mit einem Computer-Sprachmodell ‘sprechen’ durften, waren geradezu begeistert. Trotz der Tatsache, dass ‘Eliza’ in einer eher vorhersehbaren und schlechten Art und Weise antwortete, was die Komplexität der Sätze anbelangt, wurde festgestellt, dass die meisten Menschen unbewusst davon ausgingen, dass der Computer sich wie ein Mensch verhielt. Das ist recht interessant, denn jeder war sich bewusst, dass es sich nur um einen Algorithmus handelte, einen von Siliziumchips implementierten Code. Als jedoch eine fast persönliche Nachricht auf dem Bildschirm erschien, nahmen viele Menschen an, dass der Computer seine “Emotionen” und “Gedanken” mitteilte, obwohl sich unter der Maske der für Menschen verständlichen Buchstaben nur Nullen und Einsen befanden.
Auch die US-Regierung war an KI-Projekten beteiligt. Die gegründete Defence Advanced Research Projects Agency (DARPA) war vor allem an einer Maschine interessiert, die eine Echtzeit-Transkription und -Übersetzung gesprochener Sprache sowie Algorithmen für eine sehr schnelle Datenverarbeitung ermöglichen würde. Der Optimismus war groß und die Erwartungen noch größer. Im Jahr 1970 sagte Marvin Minsky, einer der Forscher auf dem Gebiet der künstlichen Intelligenz, in einer Kolumne im Life Magazine voraus, dass “in drei bis acht Jahren Maschinen geschaffen werden, die so intelligent sind wie der durchschnittliche Mensch”. Doch auch dieses Mal erwies sich die Technik als Hindernis.

Obwohl sie sich Tag für Tag weiterentwickelte, war die Entwicklung der KI-Theorie noch schneller. Es fehlte immer noch an Rechenleistung, um die theoretisch vorbereiteten Algorithmen auszuführen. Hinzu kam, dass die Sprachverarbeitung, die viele Wissenschaftler beflügelt hatte, riesige Mengen an Speicher benötigte, den es damals einfach nicht gab. Die Jahre des Wohlstands gingen zu Ende, viele Investoren zogen sich zurück und die Worte von John McCarthy wurden alltäglich – “Computer sind noch eine Million Mal zu schwach, um Intelligenz zu beweisen”. Die Errungenschaften der 1980er Jahre, die erstmals beschriebenen Deep-Learning-Techniken oder das so genannte “Experten”-Programm, ein Algorithmus, der in der Lage war, sich Informationen zu einem bestimmten Gebiet, die er von einem entsprechenden Experten erhalten hatte, einzuprägen und auf der Grundlage dieser Informationen Fragen zu beantworten, waren nicht von Nutzen.
Ironischerweise hat sich die künstliche Intelligenz in Ermangelung finanzieller Mittel und eines größeren öffentlichen Hypes entwickelt wie nie zuvor. Wir können diesen Prozess seit den späten 1990er Jahren beobachten. 1997 wird der damalige Schachmeister von Deep Blue, einem von IBM entwickelten Computerprogramm, besiegt. Im selben Jahr wird die von Dragon Systems entwickelte Spracherkennungssoftware zu einem festen Bestandteil von Windows. Die Grenzen der Rechenleistung und des Speichers, die die Entwicklung der KI rund 30 Jahre lang aufgehalten hatten, erwiesen sich als zweitrangiges Problem, und seither haben wir eine weitere historische Blüte der künstlichen Intelligenz erlebt.
Wie funktionieren künstliche neuronale Netze?
Künstliche neuronale Netze sind derzeit recht komplexe Gebilde, und man könnte sogar sagen, dass wir in mancher Hinsicht aufgehört haben, die Funktionsweise der KI zu verstehen, aber dazu später mehr. Nichts hindert uns jedoch daran, ein einzelnes Element, auf dem die heutigen neuronalen Netzwerke basieren, näher zu betrachten.
Künstliche Intelligenz versucht, die Funktionsweise des menschlichen Gehirns nachzuahmen, und so wie das Gehirn u.a. auf Neuronen basiert, beruht auch die KI auf künstlichen Neuronen, auch Perzeptronen genannt. Das Konzept dieser Art von ‘entscheidungsfindendem’ Element ist nicht neu; seine theoretischen Beschreibungen erschienen bereits in der ersten Phase der Entwicklung der künstlichen Intelligenz. Ursprünglich wurden die Neuronen physisch gebaut; ein Beispiel für ein solches Gerät, das von Marvin Minsky entworfen wurde, können Sie in einer der früheren Grafiken sehen. Wir werden uns jedoch mit dem theoretischen Konzept befassen, weil es auf seine eigene Weise faszinierend ist und weil es bemerkenswert ist, dass sogar seine grafische Darstellung einem biologischen Neuron ähnelt.
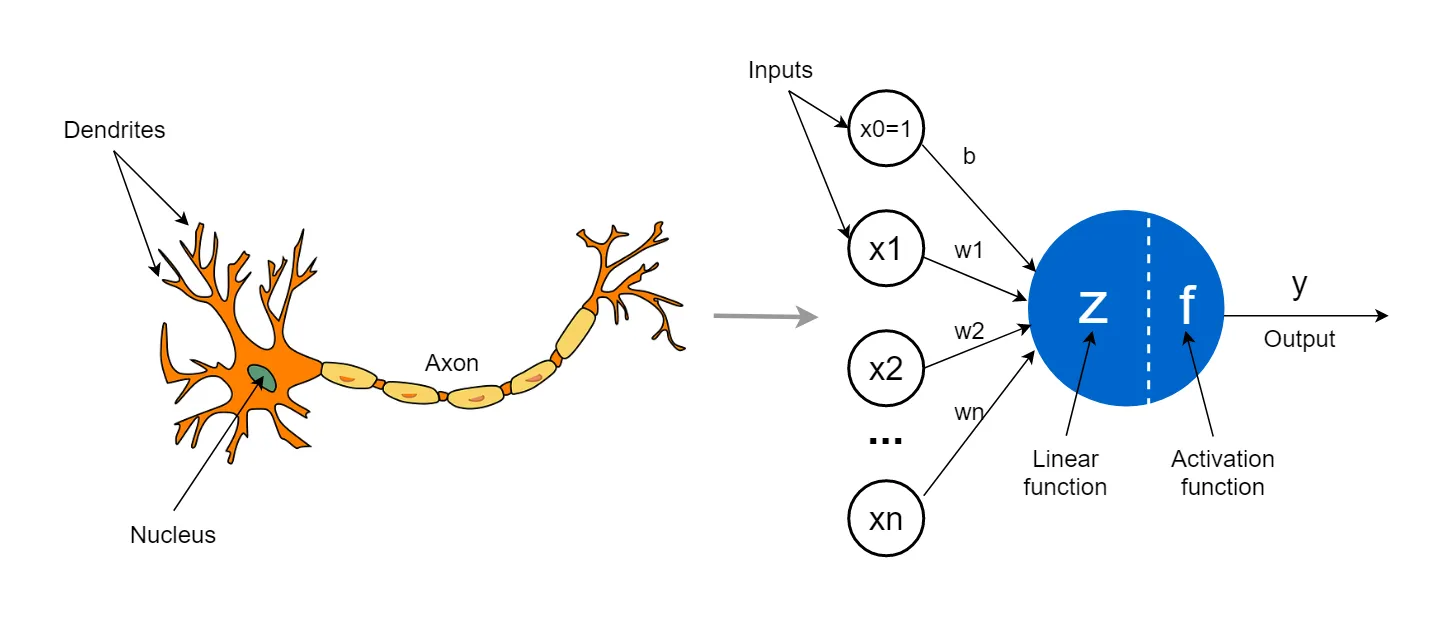
Wir können uns ein Perzeptron als ein kleines Element mit vielen Eingängen und einem einzigen Ausgang vorstellen. Über die Eingänge erhält das künstliche Neuron Informationen, die in mathematischer Form gespeichert sind und z.B. die Größe, das Gewicht und das Alter einer Person symbolisieren. Das Neuron behandelt nicht alle Informationen gleich, die Daten sind hierarchisch geordnet und einige sind wichtiger als andere. Daher wird jede Information ‘gewichtet’, d.h. mit einer speziellen Zahl, dem sogenannten Gewicht, multipliziert. Dies funktioniert ähnlich wie die aus der Schule bekannten Notengewichte. Wenn die Aufgabe eines Neurons beispielsweise darin bestünde, den Gesundheitszustand vorherzusagen, wären Informationen wie Gewicht und Alter wichtiger als die Körpergröße und würden mit einem entsprechend größeren Wert multipliziert werden.
Die vorverarbeiteten Daten werden dann addiert und dem Ergebnis wird eine kleine Zahl hinzugefügt, die als “Bias” bezeichnet wird. Diese Zahl dient als Korrektur, damit sich das Neuron etwas flexibler verhalten kann. Die resultierende Punktzahl bestimmt die endgültige Entscheidung. In einfachen Beispielen beschränkt sich dies normalerweise auf positive und negative Zahlen. In dem Beispiel, in dem das Neuron den Gesundheitszustand vorhersagt, könnten wir sagen, dass sich die Person bei einem Wert größer als Null wahrscheinlich einer guten Gesundheit erfreut und dass bei einem Wert kleiner als Null eher gesundheitliche Probleme zu erwarten sind.
Sie fragen sich vielleicht, wie ein Neuron “entscheidet”, ob das alles auf einer wundersamen Mathematik beruht, bei der ein paar Zahlen multipliziert und addiert werden? Die Antwort ist sowohl ja als auch nein. Man kann sagen, dass die ganze Magie der Funktionsweise künstlicher neuronaler Netze durch den Prozess des Lernens realisiert wird. Zu Beginn muss jedes Neuron die Rohdaten zusammen mit dem Ergebnis erhalten, damit es lernen kann, “vorherzusagen”. Dies funktioniert, indem die Informationen in aufeinanderfolgenden Paketen weitergegeben werden und der Wert der Gewichte und Korrekturen so verändert wird, dass am Ausgang das richtige Ergebnis erzielt wird. Ein auf diese Weise trainiertes Netzwerk wird, nachdem es genügend Beispiele analysiert hat, in der Lage sein, auf neue Daten zu reagieren und das richtige Ergebnis mit hoher Wahrscheinlichkeit vorherzusagen.
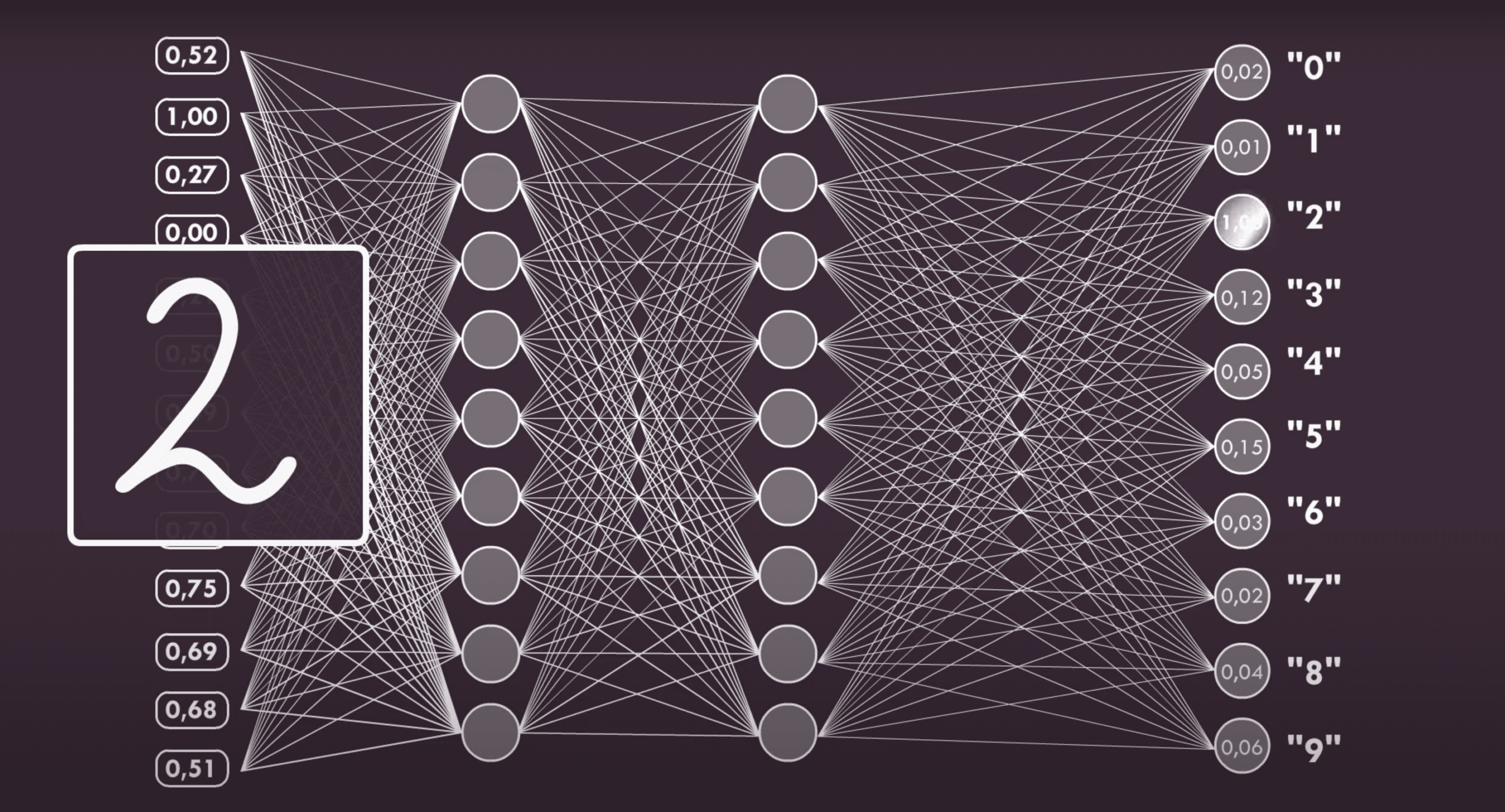
Künstliche neuronale Netzwerke können wirklich riesig sein. Ein recht bekanntes Beispiel ist ein Netzwerk, das in Abhandlungen über KI auftaucht und ein Bild analysiert, von dem angenommen wird, dass es aus 784 Pixeln in einer Konfiguration von 28×28 besteht. Seine Aufgabe ist es, eine handgezeichnete Ziffer in diesem Bereich zu erkennen. Jedes Pixel hat einen anderen Wert, der davon abhängt, ob das Pixel dunkler oder heller ist (wir bewegen uns nur im Grauspektrum, von Weiß bis Schwarz). Neuronale Netzwerke sind ebenfalls in Schichten aufgebaut. Wenn die erste Ebene beispielsweise aus 32 Neuronen besteht, hat jedes Neuron 784 Eingänge, die jedem Pixel entsprechen. In den nachfolgenden Schichten kann es mehr oder weniger Neuronen geben, aber auf der letzten Ebene gibt es zehn Neuronen, von denen jedes einer anderen Ziffer zugeordnet ist, und die an ihrem Ausgang empfangenen Ergebnisse entsprechen einer Entscheidung auf der Grundlage von ‘gezeichnet ist Null’ oder ‘nicht gezeichnet ist Null’.
Die mittleren Schichten der Neuronen können ebenfalls recht groß sein. Je mehr Schichten es gibt, desto länger dauert es, bis das Netzwerk lernt, aber es wird auch genauer sein und seine Vorhersagen näher an der Realität. Ein interessanter Aspekt ist, dass die Funktionsweise der inneren Schichten, die als versteckte Schichten bezeichnet werden, nicht vollständig verstanden wird. Obwohl es sich um reine Mathematik handelt und alle Neuronen gleich sind, stellen viele KI-Forscher das Verständnis ihrer Funktionsweise in Frage. Sie argumentieren, dass sich das selbstlernende Netzwerk ziemlich zufällig verhält und dieses Verhalten im Grunde nicht vorhergesagt werden kann, was ganz offensichtlich zu der These führt, dass wir etwas geschaffen haben, das wir nicht verstehen.
Unbegrenzte Möglichkeiten, nicht wahr?

Vor einiger Zeit wurde das offizielle KI-Modul vorgestellt, das mit dem Raspberry Pi 5 Mikrocomputer zusammenarbeitet. Das kleine Gerät, das ein M.2-Overlay verwendet, ist über den PCIe-Bus mit dem RPI-Prozessor verbunden und entlastet ihn so von seinen KI-bezogenen Berechnungen. Genauso wie der Hailo Coprozessor die CPU des Raspberry Pi 5 unterstützt, ist der intelligente Sensor Sony IMX500 in der Lage, Bilder auf der Grundlage von neuronalen Netzen zu verarbeiten. Er ist eine Komponente der RPI-spezifischen KI-Kamera, die ebenfalls vor nicht allzu langer Zeit vorgestellt wurde. Es stellt sich jedoch die Frage, warum so plötzlich Zubehör für den beliebten Mikrocontroller auftaucht, das mit künstlicher Intelligenz zu tun hat? Könnte es sein, dass der Hauptprozessor des Raspberrys mit KI nicht zurechtkommt? Wie so oft ist die Antwort nicht ganz klar.
Für seine geringe Größe und seinen Stromverbrauch kommt der Raspberry Pi 5 mit künstlichen neuronalen Netzwerken ganz gut zurecht, aber die Leistung könnte immer besser sein. Deshalb werden spezielle Module mit Chips für KI-bezogene Berechnungen entwickelt. Diese Situation veranschaulicht recht gut die aktuelle Lage in der Welt der KI. Dieser Chip entwickelt sich ziemlich schnell, aber seine Leistung wird am Ende des Tages der der besten Nvidia-Chips entsprechen.
Herkömmliche Prozessoren, die in Personalcomputern verwendet werden, sind nicht die beste Wahl für Anwendungen der künstlichen Intelligenz, da sie bei groß angelegten parallelen Berechnungen, um die es bei der KI im Wesentlichen geht, nicht gut abschneiden. Daher werden für diesen Zweck hauptsächlich Nvidia-GPUs verwendet. Diese Designs basieren auf kleinen Kernen, von denen es im Vergleich zu klassischen Prozessoren, die in der Regel ein paar oder ein Dutzend Kerne haben, relativ viele gibt. Einfache Recheneinheiten eignen sich gut für die Erstellung von Grafiken, da sie auf vielen identischen Berechnungen basieren, schließlich muss jedes Pixel einzeln erstellt werden. Bei der Erforschung der künstlichen Intelligenz haben sich GPUs auch als geeignet für künstliche neuronale Netze erwiesen.
Doch selbst moderne Grafikprozessoren sind trotz ihrer Leistung nicht ideal. Ihr ursprünglicher Zweck ist die Grafikverarbeitung, und obwohl sie bei KI-bezogenen Berechnungen gute Leistungen erbringen, ist ihre Architektur für diese Art von Aufgabe nicht perfekt geeignet. Daher können wir derzeit das langsame Aufkommen von spezialisierten ASCIs (Application-Specific Integrated Circuits) oder TPUs (Tensor Processing Units) beobachten, die für KI maßgeschneidert sind. Man kann davon ausgehen, dass es in Zukunft nur noch mehr solcher Designs geben wird. Darüber hinaus ist es nicht ausgeschlossen, dass die Entwicklung der künstlichen Intelligenz die Schaffung von etwas völlig Neuem erzwingt, das wir bisher noch nicht gesehen haben und das die KI-Welt definitiv dominieren wird.
Es zeigt sich wieder einmal, dass die Technologie für die künstliche Intelligenz ein wenig einschränkend ist. Obwohl das derzeitige Entwicklungstempo wirklich beeindruckend ist, könnte es eines Tages sein, dass die Hardware nicht mit der Software mithalten kann.
Quellen:
- https://pivotal.digital/insights/1936-alan-turing-the-turing-machine
- https://chauhaninfocom.wordpress.com/tag/history-of-computer-technology/
- https://sitn.hms.harvard.edu/flash/2017/history-artificial-intelligence/
- https://zahid-parvez.medium.com/history-of-ai-the-first-neural-network-computer-marvin-minsky-231c8bd58409
- https://www.nytimes.com/2016/01/26/business/marvin-minsky-pioneer-in-artificial-intelligence-dies-at-88.html
- https://towardsdatascience.com/the-concept-of-artificial-neurons-perceptrons-in-neural-networks-fab22249cbfc
Wie hilfreich war dieser Beitrag?
Klicke auf die Sterne um zu bewerten!
Durchschnittliche Bewertung 5 / 5. Stimmenzahl: 8
Bisher keine Bewertungen! Sei der Erste, der diesen Beitrag bewertet.






