Inhaltsverzeichnis:
Künstliche Intelligenz wird von Tag zu Tag bekannter. Es begann mit einfachen Bildanalysealgorithmen und Sprachmodellen und endete mit einer Situation, in der fast jedes Gerät etwas mit KI zu tun haben muss. Die Hersteller elektronischer Geräte aller Art übertreffen sich gegenseitig mit immer neuen Marketing-Slogans, die behaupten, dass ihre Geräte intelligenter sind. Es sieht so aus, als ob künstliche Intelligenz schon bald fast alles machen wird – E-Mails beantworten, Geburtstagswünsche ausdenken und schließlich vorschlagen, was es zum Abendessen gibt. Es bleibt jedoch die Frage, welche Rolle der Mensch bei all dem spielen wird. Denn vermutlich ist es nur der Verbraucher, der eine weitere Werbung vor dem KI-generierten Inhalt sieht (ich frage mich immer noch, warum ChatGPT noch keine Werbung implementiert hat).
Jeder will seine eigene KI, so sehr, dass ein Unternehmen beschlossen hat, das Akronym KI anders zu entwickeln und von nun an heißt es nicht mehr Künstliche Intelligenz, sondern Apple Intelligence. Man könnte sagen: „Meine künstliche Intelligenz ist mehr meine als deine“, wenn wir einen filmischen Vergleich verwenden wollen. Wie dem auch sei, AI ist eine echte Chance. Die Zeiten sind gekommen, in denen die verfügbare Rechenleistung es ermöglicht hat, wirklich ausgeklügelte Algorithmen laufen zu lassen, die sich bei mehr als einer Gelegenheit als nützlich erwiesen haben. Ein Beispiel ist eine Situation, die sich vor einiger Zeit in den Vereinigten Staaten zugetragen hat. Ein Pilotprogramm, bei dem künstliche Intelligenz die Röntgenbilder von Patienten analysierte, ermöglichte es einer Krankenschwester, ein frühes Krebsstadium zu erkennen. In einer Situation, in der die Ärzte keine Symptome festgestellt haben. Es gibt eine ganze Reihe von Bereichen, in denen KI tatsächlich viel besser ist als der Mensch, und ich persönlich bin der Meinung, dass die Technologie in erster Linie hier zum Einsatz kommen sollte, und nicht unbedingt bei der Beantwortung von E-Mails, auch wenn Bequemlichkeit und Konsumdenken wahrscheinlich überwiegen werden.
Wie jedes Unternehmen hat auch die künstliche Intelligenz ihre positiven und negativen Seiten, aber heute möchte ich mich ein wenig mehr auf letztere konzentrieren. Es gibt Stimmen aus der Branche, die sagen, dass es mit der KI nicht so bunt zugeht. Das liegt vor allem daran, dass wir nicht ganz verstehen, wie künstliche Intelligenz funktioniert. Ist dies in der Realität der Fall? Schauen wir es uns an!
Vom Traum zur Wirklichkeit

Intelligenz oder Illusion?
Das Konzept der künstlichen Intelligenz ist nicht neu. Bereits in der ersten Hälfte des 20. Jahrhunderts stellten Wissenschaftler die Theorie der lernenden Maschinen auf. Alle theoretischen Überlegungen wurden jedoch durch den damaligen Stand der Technik bestätigt. Ursprünglich war es physikalisch nicht möglich, ein System zu bauen, das als intelligent bezeichnet werden konnte. Mit der Entwicklung der Computerindustrie gab es ein Licht am Ende des Tunnels, aber die ersten Maschinen dieser Art waren auch zu primitiv, und wir mussten ziemlich lange auf den Meilenstein der künstlichen Intelligenz warten, obwohl das nicht bedeutet, dass auf diesem Gebiet nichts Interessantes geschah.
Die 1950er und 1960er Jahre waren eine Zeit der raschen Entwicklung des KI-Konzepts. Alan Turings Werk ‘Computing Machinery and Intelligence’ erscheint, in dem die theoretischen Grundlagen der künstlichen Intelligenz formuliert werden. Die ersten Lernalgorithmen und Sprachmodelle werden entwickelt, aber trotz des Optimismus von Leuten wie Marvin Minsky, der das Aufkommen intelligenter Maschinen innerhalb weniger Jahre voraussagte, erweisen sich die technologischen Grenzen als zu großes Hindernis. Der Fall der technologischen Grenzen der KI war das Thema eines meiner früheren Artikel‘Technologische Grenzen der künstlichen Intelligenz‘.
Paradoxerweise wurde die KI trotz des periodisch nachlassenden Interesses und der begrenzten finanziellen Mittel, die für die 1970er und 1980er Jahre kennzeichnend waren, weiterhin in den privaten Labors entwickelt. Die späten 1990er Jahre und das erste Jahrzehnt des 21. Jahrhunderts erweisen sich als Schlüsselmoment. Damals erblickten Projekte wie Deep Blue von IBM das Licht der Welt, dank der erheblich gestiegenen Rechenleistung von Computern. Also, das Programm, das den Schachweltmeister geschlagen hat. Oder Spracherkennungstechnologien, die in digitalen Systemen implementiert sind. Die Welt der künstlichen Intelligenz (KI) entwickelt sich immer schneller, was uns in die heutige Zeit und die zunehmende Rolle der künstlichen Intelligenz im Alltag führt.

Sollte das Sprachmodell “menschlich” sein? Sollte es Gefühle und Engagement vortäuschen? Oder sollte es bei seinen Antworten nur kalte Fakten und Logik verwenden? Interessanterweise ist diese Frage nicht die Domäne von heute. Schon bei einem der ersten Sprachmodelle, dem ‘Elizay’, hinter dem Joseph Weizenaum stand, kam so etwas wie der ‘Eliza-Effekt’ auf. Er bezog sich auf Menschen, die mit Eliza ‘sprechen’ durften und die von der Funktionsweise der frühen KI geradezu begeistert waren. Obwohl die Antworten des Computers an vielen Stellen recht dürftig und vorhersehbar waren und die Benutzer sehr wohl wussten, dass es sich nur um einen Algorithmus handelte, wurde festgestellt, dass sie unbewusst dazu neigten, anzunehmen, dass der Computer sich wie ein Mensch verhielt. Ich habe den Eindruck, dass es heutzutage ziemlich ähnlich ist, und viele ChatGPT-Nutzer unterbewusst davon ausgehen, dass die auf dem Bildschirm angezeigten Wörter in gewisser Weise Gedanken oder sogar Gefühle sind, die die Maschine uns vermittelt. Unter der Maske der Pixel auf dem Bildschirm sind es allerdings nur mehr Nullen und Einsen, und wenn wir noch tiefer gehen wollen, läuft alles auf eine elektrische Spannung hinaus.
Das menschliche Gehirn mag Vereinfachungen und Schemata. Es ist viel einfacher anzunehmen, dass der Computer in gewisser Weise eine Persönlichkeit bekommen hat und nun mit uns kommunizieren kann, als die auf dem Bildschirm angezeigten Worte zu hinterfragen und sie auf die Funktionsweise eines Algorithmus zu reduzieren. Wir scheinen die KI darauf trainiert zu haben, so zu tun, als ob sie menschlich wäre. “Der Algorithmus gibt sich große Mühe, so zu tun, als wäre er ein Mensch, was ihm übrigens sehr gut gelingt. Die Frage bleibt jedoch offen, ob das wirklich so sein sollte.
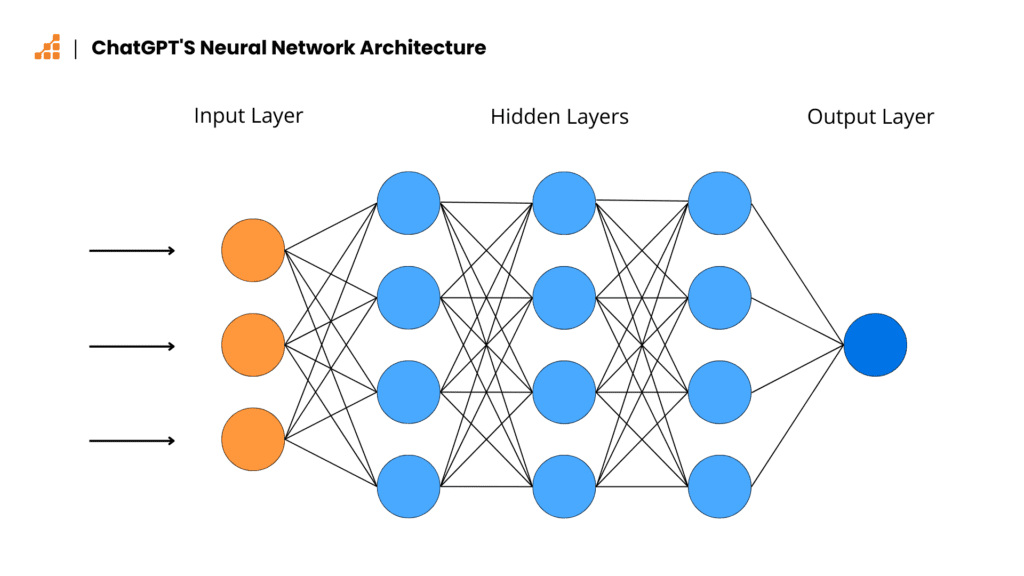
Vielleicht ist meine Herangehensweise an ChatGPT zu technokratisch, aber wenn wir unter seine Maske schauen, sehen wir nichts Intelligentes. In Wirklichkeit handelt es sich um einen mehrstufigen und entsprechend trainierten Algorithmus, dessen Funktion darauf hinausläuft, die nächsten zu erzeugenden Wörter vorherzusagen.
Das künstliche neuronale Netzwerk, auf dem ChatGPT basiert, besteht aus mit Knoten verbundenen Schichten. Die Frage, die gestellt wird, ist, ob der Befehl als Eingabe genommen wird, aber wie bei anderen Sprachmodellen sind neuronale Netzwerke im Wesentlichen komplexe mathematische Funktionen, so dass die Form ‘Wörter’ nutzlos ist. Jedem wird ein entsprechender numerischer Wert zugewiesen und nur in dieser Form werden die Daten verarbeitet. Mit anderen Worten: Jede Zeichenkette, die eine KI empfangen oder erzeugen kann, ist eigentlich ein numerischer Wert, der in für Menschen verständliche Wörter umgewandelt wird. Dadurch ist das Sprachmodell recht vielseitig und kann im Grunde jede Frage beantworten, je nach Trainingsstand mit mehr oder weniger Erfolg. Das ist einerseits ein Vorteil, andererseits aber auch ein Nachteil, durch den es Sprachmodelle so leicht haben, zu lügen.
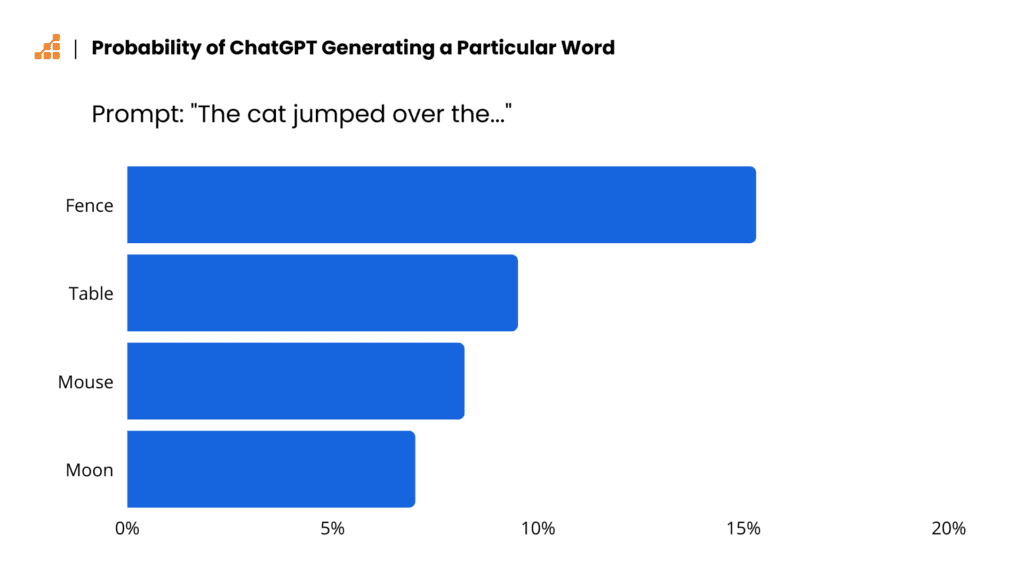
ChatGPT erstellt seine Antworten nicht als Ganzes, sondern generiert sie nur Wort für Wort. Welcher Satz der nächste ist, hängt vom Grad der Wahrscheinlichkeit eines bestimmten Wortes ab. Dies wiederum hängt vom Grad des KI-Trainings ab. In dem Satz “Die Katze sprang über den…” wäre das nächstwahrscheinliche Wort “Zaun”, obwohl das nicht bedeutet, dass dies der Satz ist, der auf dem Bildschirm erscheinen wird. In den Code von ChatGPT ist auch eine gewisse Vielfalt eingenäht, so dass ein Benutzer, der dieselbe Frage mehrmals stellt, ähnliche, aber nicht dieselben Antworten erhält. Deshalb sehen wir für den gleichen Befehl vom Typ vollständiger Satz beim ersten Mal “Die Katze ist über den Zaun gesprungen.”, aber beim nächsten Versuch wird es bereits “Die Katze ist über den Mond gesprungen” sein.

Das Trainieren von Sprachmodellen ist sozusagen ein ‘erzwungener’ Prozess. Der Algorithmus wird mit einem sogenannten Trainingsdatensatz gefüttert, bei dem es sich um Bücher, Artikel, Websites und andere Textquellen handeln kann. Je mehr es sind, desto besser, denn so kann die künstliche Intelligenz mit größerer Wahrscheinlichkeit bestimmen, welches Wort als nächstes generiert werden soll.
Es ist jedoch wichtig, sich darüber im Klaren zu sein, dass selbst das am besten trainierte Sprachmodell einen Fehler machen kann, was in manchen Fällen gefährlich sein kann. Daher ist die Wissenschaft der künstlichen Intelligenz in der Regel etwas komplexer als nur, umgangssprachlich ausgedrückt, so viele Daten wie möglich in einen Topf zu werfen und abzuwarten, was passiert. Ein menschlicher Faktor ist ebenfalls erforderlich, um zu überprüfen, ob die erzeugte Antwort ‘sicher’ ist. Ein einfaches Beispiel für diese Situation sehen Sie in der Grafik oben. Als ich die KI fragte, was ich im Falle von Kopfschmerzen tun sollte, erhielt ich ziemlich gewöhnliche Antworten, wie z.B. sich ausruhen, viel trinken und Bildschirme meiden.
Ich gehe davon aus, dass es sich dabei um Antworten handelt, die aus den gesammelten Daten generiert wurden, aber die beiden Auszüge wurden höchstwahrscheinlich aus zusätzlichen Daten erstellt, die das Modell während der Entkernung gelernt hat. Schmerzmittel (falls erforderlich) und die Worte ‘falls erforderlich’ sind hier entscheidend. Wie wir alle wissen, können Medikamente Nebenwirkungen haben, manchmal sogar ziemlich schwerwiegende. OpenAI konnte es sich also nicht leisten, dass ihr Algorithmus jedem nach Belieben Pillen vorschlägt. ChatGPT musste daher lernen, mit Medikamenten vorsichtig umzugehen. Außerdem könnte die Frage, einen Arzt zu konsultieren, aus demselben Grund wie die Vorsicht bei Medikamenten post scriptum hinzugefügt worden sein.
Zweifellos ist ChatGPT eine Art Durchbruch in der Kategorie der Sprachmodelle und der künstlichen Intelligenz. Der von OpenAI entwickelte Algorithmus funktioniert sehr gut, trotz einiger kleiner Stolperer und trotz der Tatsache, dass sich unter der Marketingmaske im Grunde keine magische künstliche Intelligenz verbirgt, sondern nur ein mathematischer Algorithmus, der richtig trainiert wurde.
Wie sieht die KI die Welt?

Wahrscheinlich sind Sie im Internet schon mehr als einmal auf Fotos in einem blauen Farbton mit der Bildunterschrift ‘So sieht ein Hund’ oder in Sepia ‘So sieht eine Katze’ gestoßen, aber haben Sie sich jemals gefragt, wie die Welt AI sieht? Es wird Sie wahrscheinlich nicht überraschen, wenn ich sage, dass sie sich von den Menschen völlig unterscheidet.
Die Analyse von Bildern mit Hilfe künstlicher Intelligenz ist etwas komplexer als der Einsatz von Sprachmodellen, obwohl auch hier alles auf Mathematik hinausläuft. Eines der einfachsten Beispiele, um besser zu verstehen, wie diese Art von Algorithmen funktioniert, ist die Ziffernerkennung. Stellen Sie sich eine Grafik vor, die aus 784 Pixeln in einer Konfiguration von 28×28 besteht und in der die schwarze Zahl zwei auf einem weißen Hintergrund gezeichnet ist. Jedes Pixel hat je nach Farbe einen anderen Wert (in einem so einfachen Beispiel gibt es natürlich nur zwei Werte, die den beiden Farben entsprechen). Grafiken werden von neuronalen Netzwerken analysiert, die größer oder kleiner sein können, aber immer aus mehreren Schichten bestehen. Wenn die erste Schicht aus, sagen wir, 64 Neuronen besteht, hat jedes Neuron bis zu 784 Eingaben für jedes einzelne Pixel. Trotz der vielen Eingänge ist der Ausgang des künstlichen Neurons nur ein einziger und wird mit den Eingängen der Elemente der nächsten Schicht verbunden. Die Daten werden Schicht für Schicht analysiert, aber im letzten Schritt gibt es nur noch zehn Neuronen, deren Ausgaben einer bestimmten Ziffer entsprechen. Wenn also die Ziffer zwei auf der Grafik gefunden wird, wird nur der Ausgang eines Neurons, der diesem Wert entspricht, aktiv sein.
Die Funktionsweise der mittleren Schichten der künstlichen Neuronen ist ein interessantes Thema, da sie noch nicht ganz bekannt ist. Obwohl das alles auf reine Mathematik hinausläuft und alle Neuronen gleich sind, weisen viele Wissenschaftler auf das eher zufällige Verhalten eines solchen Netzwerks hin. An vielen Stellen ist seine Wirkung nicht vorhersehbar, was immer die Frage aufwirft, ob wir versehentlich etwas geschaffen haben, das wir nicht verstehen.
Aber kehren wir zum Hauptthema zurück, nämlich der Frage, wie die KI die Welt sieht? Wie Sie bereits wissen, geht es bei der einfachen Bildanalyse um die Farben der einzelnen Pixel, die von einem neuronalen Netzwerk analysiert werden. Aber was passiert zum Beispiel bei einem Kamerabild? KI leistet bei solchen Anwendungen recht gute Arbeit, indem sie zuvor gelernte Muster erkennt. Hier gibt es jedoch viel mehr Pixel, so dass das Bild nicht in seiner Gesamtheit, sondern in kleineren Teilen analysiert wird. Wenn Sie sich die Grafik oben ansehen, sehen Sie eine Visualisierung dieses Prozesses. Gruppen von Pixeln, die aus einem größeren Foto extrahiert werden, bilden kleinere Bilder, die von künstlicher Intelligenz analysiert werden. Aus diesen Portionen werden dann größere Portionen erstellt, bis wir schließlich das Ergebnis erhalten und wissen, ob die KI eines der gelernten Muster erkannt hat.
Bei der Bildanalyse ähnelt das Lernen mit neuronalen Netzwerken den Sprachmodellen. Hier wird der Algorithmus jedoch nicht mit Textdaten, sondern mit spezifischen Fotos gefüttert, die das Objekt oder Phänomen darstellen, das er erkennen soll. Je mehr und je vielfältiger die Bilder sind, desto perfekter wird das Netzwerk sein und desto effektiver ist es.
Auto mit ungewuchteten Rädern
Im Jahr 2022 führten Yuri Burda und Harri Edwards, Forscher bei OpenAI, ein recht einfaches Experiment durch, bei dem sie herausfinden wollten, wie viele Beispiele für das Addieren zweier Zahlen erforderlich waren, um dem Algorithmus das Rechnen beizubringen. Sie bereiteten eine Reihe von Beispielen vor, die sie dann in das neuronale Netzwerk einspeisten, aber die Ergebnisse waren enttäuschend. Der Algorithmus gab die richtigen Ergebnisse für die Aktionen an, die ihm zuvor gezeigt worden waren, man könnte sagen, er hatte sie auswendig gelernt, aber bei anderen Beispielen waren die Antworten immer falsch. Nach dem Experiment lief der Algorithmus jedoch noch zwei Tage lang weiter. Während dieser Zeit analysierte er immer wieder die Beispiele, die er bereits in der ersten Lernphase gesehen hatte. Nach dieser Zeit beschlossen Burda und Edwards, die Leistung der KI noch einmal zu testen. Zu ihrer Überraschung stellte sich heraus, dass das Netzwerk korrekt funktionierte und darüber hinaus in der Lage war, korrekte Ergebnisse für Aktionen zu liefern, die nicht im Lernpool enthalten waren. Die Situation sah ziemlich seltsam aus, denn sie widersprach den Prinzipien des maschinellen Lernens. Es sah so aus, als ob der Algorithmus, gefüttert mit immer denselben Daten, plötzlich die Fähigkeit erlangte, zu addieren, was nicht passieren sollte.
Die Situation wurde in der Technologiebranche weithin als etwas Ungewöhnliches kommentiert. Sie warf auch die Frage auf, ob wir sicher sein können, dass künstliche neuronale Netzwerke jemals aufhören zu lernen? Vieles deutet darauf hin, dass dies der Fall ist, und obwohl die Algorithmen theoretisch anhand ausgewählter Daten angelernt werden, lernen sie weiter, nachdem sie ausgeführt wurden, und zwar bereits an den Proben, die sie analysieren müssen. Dieses Phänomen wird als ‘Grokking’ bezeichnet, und viele behaupten, dass jedes ‘seltsame’ Verhalten von Sprachmodellen darauf zurückzuführen ist. Mit der Zeit werden es immer mehr. Sie weigern sich, Fotos von weißen Menschen zu erstellen, Algorithmen schlagen Scheidung oder sogar Selbstmord zum Wohle des Planeten vor. Es gab bereits Berichte über diese Art von Fällen im Internet, bei denen es sich laut den Herstellern in der Regel um ein “unvorhergesehenes algorithmisches Verhalten” handelte, das nun behoben wurde, aber sind wir sicher?
Grokking ist nur eines von mehreren seltsamen Phänomenen, die künstliche Intelligenz umgeben. Erstaunlich ist auch, dass große Sprachmodelle die Fähigkeit aufweisen, verschiedene Arten von Wissen zu kombinieren, obwohl eine solche Funktionalität für sie nicht implementiert wurde. Ein Modell, dem mathematische Prinzipien auf Englisch beigebracht wurden, kann dieselben Probleme auf Französisch lösen, auch wenn ihm die mathematischen Prinzipien nicht in dieser Sprache beigebracht wurden. Es sieht so aus, als ob das Modell die Daten, die ihm beigebracht wurden, selbständig übersetzen kann, indem es Mathematik und Linguistik kombiniert.
Die Forscherin Hattie Zhou, die an der Universität von Montreal und im KI-Team von Apple arbeitet, weist darauf hin, dass die Fortschritte im Bereich des Deep Learning in den letzten zehn Jahren eher durch Versuche und Experimente als durch ein bewusstes Verständnis von künstlicher Intelligenz erzielt wurden. Das alles ist eher ein Produkt des Zufalls, wir haben zufällig ein paar Elemente zu einem funktionierenden Ganzen zusammengefügt, aber wir wissen nicht wirklich, wie das Ganze funktioniert. Forscher wie Andrzej Dragan und Tomasz Czajka, kommen ebenfalls zu ähnlichen Ergebnissen.
Natürlich wird erforscht, wie KI funktioniert, aber wir scheinen selbst in die Falle der Allgegenwart von künstlicher Intelligenz getappt zu sein. Derzeit möchte jeder seine eigene KI haben. Das klingt irgendwie magisch und treibt das Marketing an, obwohl die heutige künstliche Intelligenz wirklich nichts Intelligentes an sich hat.
Vieles deutet darauf hin, dass der Spaß an künstlicher Intelligenz gerade erst beginnt. Boaza Barak, Informatiker an der Harvard University, vergleicht den heutigen Stand der Technik mit der Physik des frühen 20. Jahrhunderts. Wir wissen, dass einige Dinge funktionieren und andere nicht, aber warum ist das so? Diese Frage bleibt offen. Das Hauptziel der heutigen KI-Forschung besteht in erster Linie darin, das Innere der künstlichen Intelligenz besser zu verstehen, denn ohne dies können wir nur Fehler und verschiedene unvorhersehbare Verhaltensweisen der KI erwarten.
Quellen:
- https://www.scalablepath.com/machine-learning/chatgpt-architecture-explained
- https://distill.pub/2019/activation-atlas/
- https://engineering.stanford.edu/news/stanfords-john-mccarthy-seminal-figure-artificial-intelligence-dead-84
- https://www.technologyreview.com/2024/03/05/1089449/nobody-knows-how-ai-works/
- https://www.youtube.com/watch?v=UZDiGooFs54
- https://www.technologyreview.com/2024/03/04/1089403/large-language-models-amazing-but-nobody-knows-why/?truid=&utm_source=the_algorithm&utm_medium=email&utm_campaign=the_algorithm.unpaid.engagement&utm_content=03-04-2024
- https://distill.pub/2017/feature-visualization/
- https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- https://arxiv.org/abs/2201.02177
Wie hilfreich war dieser Beitrag?
Klicke auf die Sterne um zu bewerten!
Durchschnittliche Bewertung 5 / 5. Stimmenzahl: 12
Bisher keine Bewertungen! Sei der Erste, der diesen Beitrag bewertet.






